接上文Scrapy-Redis爬虫贝壳网所有在售厦门二手房信息,总共爬到2.25K的在售二手房信息,这篇文章初步清晰数据,为进一步分析做准备,本文仅做交流学习用途。
系列文章:
- Scrapy-Redis爬虫贝壳网所有在售厦门二手房信息
- 本文->初步清理贝壳网爬取的厦门二手房信息
- 百度API补完厦门二手房经纬度并找到最近的地铁站
- 简单分析贝壳在售厦门二手房数据(一)
- 简单分析贝壳在售厦门二手房数据(二)
- 进行中:进一步手机和处理数据/建模
字段有这些:
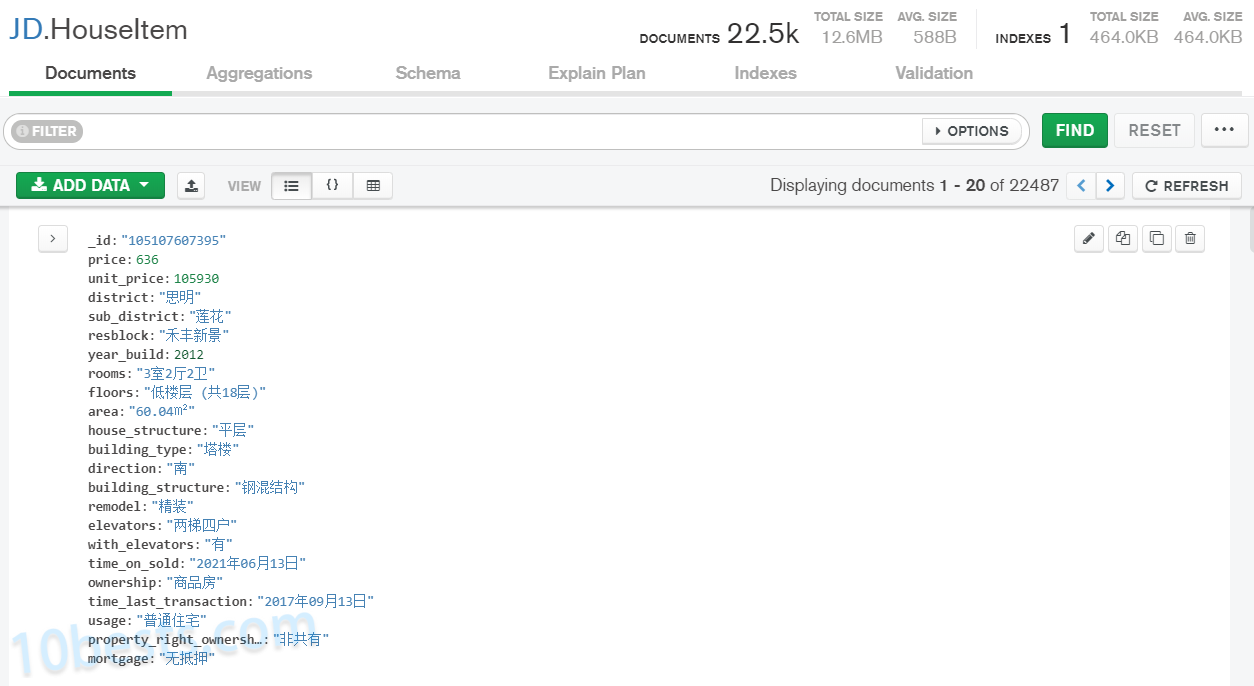

一、准备工作
# 导入相关包
import time
from mongoConn import MongoDBConnection # 这个文件前文有
import pandas as pd
from utils import *
# pandas的一些设置,打印数据看起来舒服些
# pandas.DataFrame显示所有列
pd.set_option('display.max_columns', None)
# pandas.DataFrame显示所有行
pd.set_option('display.max_rows', None)
# 设置pandas.DataFrame的value的显示长度为100,默认为50
pd.set_option('max_colwidth', 100)
# 设置pandas.DataFrame 显示不换行
pd.set_option('display.width', 10086)二、查看并确定要清理的字段
# 查看各自字段值的分布
print(data_pre['district'].value_counts())
print(data_pre['building_type'].value_counts())输出结果类似:
板楼 9362
塔楼 5093
板塔结合 3602
暂无数据 518
平房 181
Name: building_type, dtype: int64确定以下字段需要整理:
# 以下字段需要清洗:
['elevators', 'house_structure', 'direction', 'remodel', 'with_elevators', 'mortgage', 'ownership', 'usage', 'property_right_ownership', 'time_on_sold', 'time_last_transaction']三、清理数据的函数
def clean_data(item):
"""
这是初步整理从本地mongo库取出的HouseItem实例的函数,
"""
# 这些字段同时存在 None 和 '暂无数据',全部替换成None:
if item.get('floors'):
item['floors'] = None if '暂无数据' in item['floors'] else item['floors']
if item.get('rooms'):
item['rooms'] = None if '暂无数据' in item['rooms'] else item['rooms']
if item.get('building_type'):
item['building_type'] = None if '暂无数据' in item['building_type'] else item['building_type']
if item.get('house_structure'):
item['house_structure'] = None if '暂无数据' in item['house_structure'] else item['house_structure']
if item.get('time_on_sold'):
item['time_on_sold'] = None if '暂无数据' in item['time_on_sold'] else item['time_on_sold']
if item.get('time_last_transaction'):
item['time_last_transaction'] = None if '暂无数据' in item['time_last_transaction'] else item['time_last_transaction']
if item.get('mortgage'):
item['mortgage'] = None if '暂无数据' in item['mortgage'] else item['mortgage']
# 这些字段的值同时存在 None 和 '未知',全部替换成None:
if item.get('building_structure'):
item['building_structure'] = None if '未知' in item['building_structure'] else item['building_structure']
# 清理电梯和户数: '两梯四户'
# 提取(两)->(2),保存到'elevators'字段
# 提取(四)->(2),保存到'house_per_floor'字段
if item.get('elevators'):
elevator_count = re.search('(.+?)梯(.+?)户', item['elevators'])[1]
house_per_floor = re.search('(.+?)梯(.+?)户', item['elevators'])[2]
elevator_count = tr_zn_to_digit(elevator_count)
house_per_floor = tr_zn_to_digit(house_per_floor)
item['elevators'] = int(elevator_count)
# 新增house_per_floor属性
item['house_per_floor'] = int(house_per_floor)
item['with_elevators'] = True
item['with_elevators'] = True if item.get('with_elevators') else False
# 抽取抵押贷款金额保存到原字段: '有抵押 75万元 农业银行 客户偿还'
if item.get('mortgage'):
if '有抵押' in item['mortgage']:
# 有抵押/贷款,并且给出具体金额(万)
if re.search(r'(\d+?)万', item['mortgage']):
item['mortgage'] = re.search(r'(\d+?)万', item['mortgage'])[1]
# 有抵押/贷款,未给出具体金额(万)
else:
item['mortgage'] = None
else:
# 无抵押
item['mortgage'] = 0
# 整理朝向'direction'从东开始顺时针排序 '东南 东 西'
if item.get('direction'):
sort_directions = ['东', '东南', '南', '西南', '西', '西北', '北', '东北'] # 从东开始顺时针共八个方向
ori_directions = [i.strip() for i in item['direction'].split()]
new_directions = []
for direction in sort_directions:
if direction in ori_directions:
new_directions.append(direction)
item['direction'] = ' '.join(new_directions)
# 清理面积'area',: '60.04㎡', 去掉单位,转浮点
if item.get('area'):
item['area'] = float(item['area'][0:-1])
# 清理楼层: "低楼层 (共18层)“
if item.get('floors'):
# 总层高18保存到'building_floors'字段
item['building_floors'] = int(re.search(r'(\d+?)层', item['floors'])[1])
# 楼层概括'低楼层'保存到'floors'字段
item['floors'] = re.search(r'(.+?)\(.*\)', item['floors'])[1]
# 小区'resblock': '7#地块' -> 7号地块
if item.get('resblock'):
if re.search('#', item['resblock']):
item['resblock'] = re.sub('#', '号', item['resblock'])
return item用以上函数清理数据:
data_clean = []
for house in all_houses:
data_clean.append(clean_data(house))四、保存到表格文件备用
# 写入到data_clean.csv文件备用:
data_clean = pd.DataFrame(data_clean)五、还需要地铁站和BRT站的数据
整理完的数据已经好看多了,打印看看:
data_clean = pd.read_csv('data_clean.csv')
print(data_clean[0:5])
不过现在还缺少房子和地铁站的位置(经纬)数据,贝壳二手房详情页上的房子位置信息是js加载的,我们不能直接拿到,有了这些数据我们才能算房子到最近地铁站的距离,这应该是影响房价很重要的数据。
所以接下来就是要通过调用百度API拿到这些房子以及厦门轨道交通的的经纬度:
原创文章,作者:10bests,禁止任何形式转载:https://www.10bests.com/clean-xiamen-beike-house-data/