Scrapy-Redis爬虫贝壳网所有在售厦门二手房信息
贝壳网的反爬不算厉害,做好Referer和随机UA,并适当限制并发基本就没问题了。
分享代码,仅做学习交流用途,系列文章:
- 本文->Scrapy-Redis爬虫贝壳网所有在售厦门二手房信息
- 初步清理贝壳网爬取的厦门二手房信息
- 百度API补完厦门二手房经纬度并找到最近的地铁站
- 简单分析贝壳在售厦门二手房数据(一)
- 简单分析贝壳在售厦门二手房数据(二)
- 进行中:进一步手机和处理数据/建模
一、RedisSpider爬虫类代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
__author__ = 'Luke'
__mtime__ = '2021/06'
"""
import json
import logging
import re
import time
from scrapy.http import Request
from scrapy_redis import defaults
from scrapy_redis.spiders import RedisSpider
from ..extensions import BanThrottle
from ..items import *
from ..mongoConn import MongoDBConnection
class JDSpider(RedisSpider):
name = "BKSpider"
redis_key = 'BKSpider:start_urls'
logging.getLogger("requests").setLevel(logging.CRITICAL) # 将requests的日志级别设成WARNING
def __init__(self):
# 初始化
self.mongoConn = MongoDBConnection()
self.Requests = self.mongoConn.DBCollections['RequestItem']
self.cats_saved = []
self.brands_saved = []
self.add_tast_cycle = 100866666
# 抽取值对应的字段
self.label_content_pairs = {
'房屋户型': 'rooms',
'所在楼层': 'floors',
'建筑面积': 'area',
'户型结构': 'house_structure',
'建筑类型': 'building_type',
'房屋朝向': 'direction',
'建筑结构': 'building_structure',
'装修情况': 'remodel',
'梯户比例': 'elevators',
'挂牌时间': 'time_on_sold',
'上次交易': 'time_last_transaction',
'交易权属': 'ownership',
'抵押信息': 'mortgage',
'房屋用途': 'usage',
'产权所属': 'property_right_ownership',
'配备电梯': 'with_elevators'
}
def next_requests(self):
"""
重写next_requests方法,source_url干涸后定时自动添加任务
"""
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
fetch_one = self.server.spop if use_set else self.server.lpop
# XXX: Do we need to use a timeout here?
found = 0
while found < self.redis_batch_size:
data_raw = fetch_one(self.redis_key) # 从redis中取出内容
if not data_raw:
break
data = json.loads(data_raw) # 存入redis的内容是json,需要转化
if "source_url" not in data:
break
if "dont_filter" not in data:
data['dont_filter'] = False
req = Request(url=data['source_url'], meta=data.get('meta'),
headers={'Referer': data.get('Referer')}, dont_filter=data.get('dont_filter')) # 发出请求
if req:
yield req
found += 1
else:
self.logger.debug("Request not made from data: %s", data)
if found:
self.logger.debug("Read %s requests from '%s'", found, self.redis_key)
elif self.crawler.engine.slot.scheduler.__len__() == 0 and self.crawler.engine.slot.inprogress.__len__() == 0:
self.feed_source_url(use_set)
def feed_source_url(self, use_set):
"""
按时添加任务的函数
"""
# 最近一次添加任务时间记录在LogItem{'key': 'last_add_bk_tast'}
last_add_bk_tast = self.mongoConn.get_log_item('last_add_bk_tast')
if time.time() - last_add_bk_tast['value'] > self.add_tast_cycle:
# add_tast_cycle
input_one = self.server.sadd if use_set else self.server.ladd
success = self.mongoConn.add_spider_tast(input_one)
if success:
self.logger.warning("success adding new task")
self.mongoConn.update_log_item(last_add_bk_tast)
def parse(self, response):
"""
解析贝壳厦门二手房首页:https://xm.ke.com/ershoufang/
yield 6个区的Request任务
"""
print(response.url)
district_urls = response.xpath('//div[@data-role="ershoufang"]/div/a/@href').extract()[0:6]
headers = {'Referer': response.url}
for district_url in district_urls:
yield Request(url=self.base_url + district_url, callback=self.parse_district_list_page, headers=headers,
dont_filter=True)
def parse_district_list_page(self, response):
"""
解析贝壳厦门6个区在售二手房页面
yield 各个街道二手房列表页面Request任务
"""
params = {'current_page': 1}
sub_district_urls = response.xpath('//div[@data-role="ershoufang"]/div/a/@href').extract()[6:]
headers = {'Referer': response.url}
for sub_district_url in sub_district_urls:
yield Request(url=self.base_url + sub_district_url, callback=self.parse_sub_district_list_page, meta={'params': params}, headers=headers,
dont_filter=True)
def parse_sub_district_list_page(self, response):
"""
解析贝壳厦门各个街道二手房列表页面
yield 分页Request任务
yield 详情页Request任务
"""
params = response.meta.get('params')
if params and params.get('current_page') == 1:
page_data = response.xpath('//div[contains(@class,"house-lst-page-box")]/@page-data').get()
page_data = json.loads(page_data)
for i in range(page_data['curPage'], page_data['totalPage']):
# response.url case: "https://xm.ke.com/ershoufang/bailuzhou/"
next_page_url = response.url + 'pg%s/' % str(i+1)
headers = {'Referer': response.url}
yield Request(url=next_page_url, callback=self.parse_sub_district_list_page, headers=headers,
dont_filter=True)
house_items = response.xpath('//li[@class="clear"]')
for house_item in house_items:
house_base_url = house_item.xpath('./div[@class="info clear"]//div[@class="title"]/a/@href').get()
data_maidian = house_item.xpath('./div[@class="info clear"]//div[@class="title"]/a/@data-maidian').get()
if house_base_url and data_maidian:
house_full_url = house_base_url + '?fb_expo_id=%s' % str(460233438474899459)
headers = {'Referer': response.url}
yield Request(url=house_full_url, callback=self.parse_house_info, meta={'params': params},
headers=headers, dont_filter=False)
def parse_house_info(self, response):
"""
解析贝壳厦门二手房详情页任务
简单数据清理
yield HouseItem
"""
# response_url:https://xm.ke.com/ershoufang/105107607395.html?fb_expo_id=460233438474899459
house_item = HouseItem()
# 价格和区域
house_item['_id'] = response.url.split('.html')[0].split('/').pop()
house_item['price'] = float(response.xpath('//div[@class="price "]/span//text()').get())
house_item['unit_price'] = float(response.xpath('//div[@class="unitPrice"]/span//text()').get())
house_item['district'] = response.xpath('//div[@class="areaName"]/span[@class="info"]/a//text()').extract()[0]
house_item['sub_district'] = response.xpath('//div[@class="areaName"]/span[@class="info"]/a//text()').extract()[1]
house_item['resblock'] = response.xpath('//a[@class="info no_resblock_a"]//text()').get()
# 基本属性 no_resblock_a
if re.search('(\d{4})年建', response.text):
house_item['year_build'] = int(re.search('(\d{4})年建', response.text)[1])
info_li_xpathes = response.xpath('//div[@class="introContent"]/div/div/ul/li')
for info_li_xpath in info_li_xpathes:
content_texts = info_li_xpath.xpath('.//text()').extract()
if content_texts[0].strip() in self.label_content_pairs:
if type(content_texts[1]) == str:
house_item[self.label_content_pairs[content_texts[0].strip()]] = content_texts[1].strip().replace('\n', '')
yield house_item二、MongoDB数据量连接对象
文件名 mongodb.py
import configparser
import inspect
import json
import logging
import time
import pymongo
import redis
import items
from items import *
# 把items.py里面所有类名加写到这里,自动初始化mongodb数据量连接对象
all_collections = ['LogItem']
class MongoDBConnection(object):
def __init__(self):
# 初始化数据库连接
cf = configparser.ConfigParser()
cf.read('../scrapy.cfg')
client = pymongo.MongoClient(cf.get("mongodb", "host"), cf.getint("mongodb", "port"))
self.db = client.admin
self.db.authenticate(cf.get("mongodb", "user"), cf.get("mongodb", "pass"), mechanism=cf.get("mongodb", "mech"))
self.db = client[cf.get("mongodb", "db")]
# self.db = client['Storage']
self.DBCollections = dict()
clsmembers = inspect.getmembers(items, inspect.isclass)
for (name, value) in clsmembers:
if issubclass(value, Item) and value != Item:
self.DBCollections[name] = self.db[name]
def update_item(self, item):
"""
插入一条记录,
自动根据类名判断要插到哪个表
"""
item_class_name = item.__class__.__name__
# if item_class_name == 'dict':
if item_class_name not in self.DBCollections:
self.DBCollections[item_class_name] = self.db[item_class_name]
try:
self.DBCollections[item_class_name].insert(dict(item))
except pymongo.errors.DuplicateKeyError as e:
condition = {'_id': item['_id']}
self.DBCollections[item_class_name].update_one(condition, {'$set': dict(item)})
except Exception as e:
logging.critical('-=-=-=-=-mongo-update-item-exception-=-=-=-=-')
logging.critical(e.args)
logging.critical(item)
return item
def add_spider_tast(self, input_one):
"""
添加爬虫任务的方法
"""
params_list = {'page': 1,
'base_url': 'https://xm.ke.com/ershoufang/'
}
start_info_list = {
"source_url": 'https://xm.ke.com/ershoufang/',
"Referer": 'https://xm.ke.com/',
"meta": {'params': params_list},
"dont_filter": True
}
start_info_json = json.dumps(start_info_list) # 将字典转化为json
if input_one:
success = input_one('BKSpider:start_urls', start_info_json)
else:
redis_pool = redis.ConnectionPool(host='192.168.0.218', port=6379, password='Pyth.2021', db=0)
redis_conn = redis.Redis(connection_pool=redis_pool)
success = redis_conn.sadd('BKprocess:start_urls', start_info_json) # 存入内容
return success
def get_log_item(self, key):
"""
取出'key'为key的的一项LogItem,若库中无记录,则返回{'key': key, 'value': 0}
"""
result = self.fetch_one('LogItem', filter={'key': key})
if not result:
result = LogItem({'key': key, 'value': 0})
return result
def update_log_item(self, item, update_time=True):
"""
更新一项LogItem,默认更新'value'为当前时间time.time()
"""
if update_time:
item['value'] = time.time()
self.update_item(item)
def fetch_one(self, class_name, filter={}, sort=None, ran=False):
"""
从class_name表中取出一条记录
:param class_name: str, 取出数据类名/也是表名
:param filter: object, 过滤条件
:param sort: object, 排序
:param ran: bool, 是否随机
:return: Class_name(Item)实例 or None
"""
if ran:
total = self.db[class_name].count(filter=filter)
skip_count = random.randint(0, total - 1)
else:
skip_count = 0
data = self.db[class_name].find(filter=filter, sort=sort).limit(1).skip(skip_count)
# data = self.db[class_name].find_one(filter=filter, sort=sort)
if data:
try:
instance = eval(class_name + '(data[0])')
return instance
except IndexError:
return None
return None
def fetch_many(self, class_name, filter={}, sort=None, limit=0):
"""
从class_name表中取出(limit)条记录
:param class_name: str, 取出数据类名/也是表名
:param filter: object, 过滤条件
:param sort: object, 排序
:param limit: int, 最多取出(limit)条
:return: [Class_name(Item)实例...] or []
"""
datas = self.db[class_name].find(filter=filter, sort=sort, limit=limit)
instances = []
for data in datas:
instance = eval(class_name + '(data)')
instances.append(instance)
return instances
三、MongoDB配置写到scrapy.cfg
[mongodb]
host = 192.168.0.xxx
port = 27017
user = xxx
pass = xxx
mech = SCRAM-SHA-1
db = xxx四、items.py文件
# -*- coding: utf-8 -*
from scrapy import Item, Field
class HouseItem(Item):
_id = Field() # url结尾的数串
resblock = Field() # 禾丰新景
price = Field() # 636万
unit_price = Field() # 105930
district = Field() # 思明
sub_district = Field() # 思明
# 基本属性
year_build = Field() # 2012
rooms = Field() # 3室2厅2卫
area = Field() # 60.04
building_type = Field() # 塔楼
building_structure = Field() # 钢混结构
elevators = Field() # 两梯四户
floors = Field() # 低楼层(共18层)
house_structure = Field() # 平层
direction = Field() # 南
remodel = Field() # 精装
with_elevators = Field() # 两梯四户
# 交易属性
time_on_sold = Field() # 2021年06月13日
time_last_transaction= Field() # 2017年09月13日
mortgage = Field() # 无抵押
ownership = Field() # 商品房
usage = Field() # 普通住宅
property_right_ownership = Field() # 普通住宅
# 清洗属性
house_per_floor = Field() # 一梯(几)户
building_floors = Field() # 总层高
class LogItem(Item):
_id = Field()
key = Field() # 键
value = Field() # 值
五、结果
上图,一早上2万多条记录,厦门贝壳它已经干了:
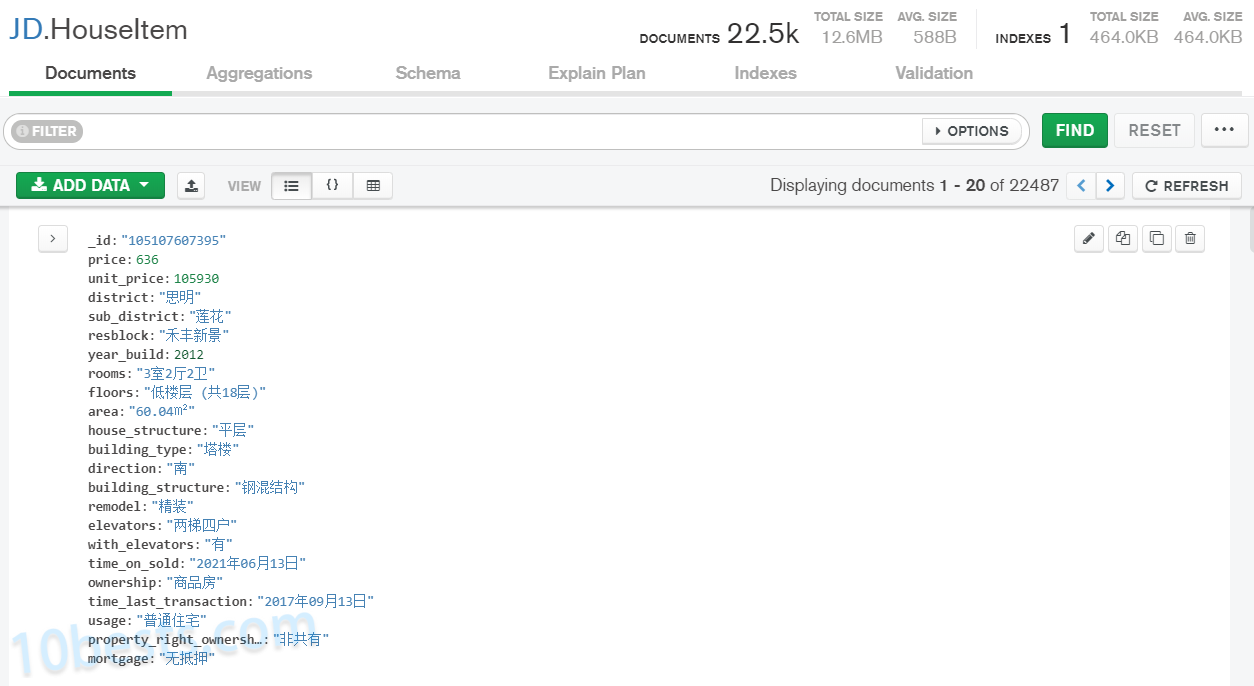

这样的数据是用不了的,还要进一步清理:初步清理贝壳网爬取的厦门二手房信息
突然又有其他想法:
# 其他想法:爬成交价,比较与挂牌价之间的关系
# 其他想法:爬租房,统计租售比 先放一放吧,这贝壳网这两个页面和二手房页面结果是不一样的,时间紧迫!
原创文章,作者:10bests,禁止任何形式转载:https://www.10bests.com/scrapy-redis-crawl-beike-xiamen/
相关推荐
-
简单分析贝壳在售厦门二手房数据(二)
这是我的python数据可视化练手项目,数据从贝壳厦门二手房网爬取,数据已经经过清理,并且补充了经纬和地铁/BRT站信息,这是数据分析的第二部分,系列文章: Scrapy-Redi...
-
百度API补完厦门二手房经纬度并找到最近的地铁站
经纬度是二手房的重要信息,有了这些数据我们才能计算房子到最近地铁站的距离,轨道交通是影响房价很重要的数据。贝壳二手房详情页上的房子位置信息是js加载的,我们不能直接拿到,所以只能找...
-
贝壳在售厦门二手房数据建模
还在写,先发布了,以表决心! 系列文章: Scrapy-Redis爬虫贝壳网所有在售厦门二手房信息 初步清理贝壳网爬取的厦门二手房信息 百度API补完厦门二手房经纬度并找到最近的地...
-
初步清理贝壳网爬取的厦门二手房信息
接上文Scrapy-Redis爬虫贝壳网所有在售厦门二手房信息,总共爬到2.25K的在售二手房信息,这篇文章初步清晰数据,为进一步分析做准备,本文仅做交流学习用途。 系列文章: S...
-
简单分析贝壳在售厦门二手房数据(一)
这是我的python数据可视化练手项目,数据从贝壳厦门二手房网爬取,数据已经经过清理,并且补充了经纬和地铁/BRT站信息,系列文章: Scrapy-Redis爬虫贝壳网所有在售厦门...
-
美味可口冬日汤圆十大排行
汤圆是元宵节的节日食品,也是冬日里的暖心之物。汤圆在速冻食品里有许多牌子可以选择,那么,哪些冬日汤圆美味可口呢?下面小编为您推荐美味可口冬日汤圆十大排行! 美味可口冬日汤圆十大排行...